graph TD
A["Player A History (10 × seq_features)"] -->|"Shared LSTM"| E1["Momentum Embedding A"]
B["Player B History (10 × seq_features)"] -->|"Shared LSTM"| E2["Momentum Embedding B"]
C["Match Context (23 features)"] --> F["Fusion Layer"]
E1 --> F
E2 --> F
F -->|"Dense 64 → Dense 32 → Dense 1"| O["Win Probability"]
BreakPoint AI: Forecasting ATP Tennis with Sequential Deep Learning
Python
PyTorch
Optuna
XGBoost
Time-Series
Ensemble Learning
0.717
Ensemble AUC
AUC do Ensemble
2024 unseen test set
Conjunto de teste 2024
65.5%
Best Accuracy
Melhor Acurácia
Siamese LSTM
90K+
ATP Match Records
Registros de Partidas ATP
1990 – 2024
The Problem with Static FeaturesO Problema das Features Estáticas
A player’s season average tells you who they are. Their last 10 matches tell you who they are right now. A média da temporada de um jogador diz quem ele é. As últimas 10 partidas dizem quem ele é agora.
Standard tabular models collapse match histories into single static numbers — “65% first serve in,” “2.4 aces per match.” This loses the temporal signal entirely. A player on a 7-match losing streak and a player who just won a Masters title might share identical season averages, but they are not equivalent forecasting targets. Modelos tabulares padrão reduzem históricos de partidas a números estáticos — “65% de primeiro serviço,” “2,4 aces por partida.” Isso elimina o sinal temporal por completo. Um jogador em uma sequência de 7 derrotas e um jogador que acabou de vencer um Masters podem ter médias idênticas na temporada, mas não são alvos de previsão equivalentes.
BreakPoint AI treats each match as the collision of two historical trajectories. The architecture is designed around one question: can a model learn momentum patterns directly from raw sequential data, without manual feature smoothing? BreakPoint AI trata cada partida como a colisão de duas trajetórias históricas. A arquitetura é projetada em torno de uma única pergunta: um modelo pode aprender padrões de momentum diretamente de dados sequenciais brutos, sem suavização manual de features?
Temporal Validation — The Silent Failure ModeValidação Temporal — O Erro Silencioso
Look-ahead bias is the most common — and most quietly damaging — failure mode in sequential forecasting. If any future information leaks into the training set, results are meaningless. The model hasn’t learned to predict; it has learned to cheat. O viés de look-ahead é o erro mais comum — e mais silenciosamente prejudicial — em previsão sequencial. Se qualquer informação futura vazar para o conjunto de treinamento, os resultados são inválidos. O modelo não aprendeu a prever; aprendeu a trapacear.
Every design decision in this project was made with leakage prevention as a hard constraint: Cada decisão de design neste projeto foi tomada com a prevenção de vazamento como restrição inegociável:
Temporal splits: Train ≤ 2022, Validation = 2023, Test = 2024. No shuffling. No cross-validation across time boundaries. Divisões temporais: Treino ≤ 2022, Validação = 2023, Teste = 2024. Sem embaralhamento. Sem validação cruzada além das fronteiras temporais.
Rolling features with shift(1): Every rolling statistic is computed over the 10 matches before the current one. The current match is never part of its own feature window. Features de janela deslizante com shift(1): Toda estatística de janela é calculada sobre as 10 partidas anteriores à atual. A partida atual nunca faz parte de sua própria janela de feature.
LSTM sequence filter: The _get_sequence() function enforces candidate_dates < current_date (strict less-than) — one character that eliminates an entire class of leakage. Filtro de sequência LSTM: A função _get_sequence() aplica candidate_dates < current_date (estritamente menor) — um caractere que elimina uma classe inteira de vazamento.
Preprocessor isolation: StandardScaler and OneHotEncoder are fit on the training split only, then applied to validation and test. Fitting on the full dataset would encode distributional information from the future. Isolamento do pré-processador: StandardScaler e OneHotEncoder são ajustados apenas no conjunto de treino. Ajustar no conjunto completo codificaria informações distribucionais do futuro.
System ArchitectureArquitetura do Sistema
Feature EngineeringEngenharia de Features
Raw ATP match logs (1990–2024, ~90,000 records) are transformed into a feature matrix across seven groups. Every group uses shift(1) before any aggregation: Os registros brutos de partidas ATP (1990–2024, ~90.000 registros) são transformados em uma matriz de features em sete grupos. Cada grupo usa shift(1) antes de qualquer agregação:
| Feature GroupGrupo de Features | ExamplesExemplos |
|---|---|
| Rolling form (10-match window)Forma recente (janela de 10 partidas) | Win rate, ace rate, double fault rate, serve pointsTaxa de vitórias, aces, duplas faltas, pontos de saque |
| Surface-specific win rateTaxa de vitória por superfície | Clay, grass, hard court form tracked separatelyForma em saibro, grama e quadra dura rastreadas separadamente |
| Serve efficiencyEficiência de saque | BP save rate, 1st/2nd serve win %, rolled over 10 matchesTaxa de salvamento de break-points, % de pontos ganhos no 1º/2º saque |
| Rank qualityQualidade de ranking | Log-transformed rank points differentialDiferencial de pontos de ranking com transformação logarítmica |
| MomentumMomentum | Signed win/loss streak counter, rank trend over 5 matchesContador com sinal de sequência de vitórias/derrotas, tendência de ranking |
| H2H | Overall and surface-specific head-to-head win rateTaxa de vitória head-to-head geral e por superfície |
| ContextContexto | Rank difference, days since last match (fatigue proxy)Diferença de ranking, dias desde a última partida (proxy de fadiga) |
Siamese LSTM ArchitectureArquitetura Siamese LSTM
The deep learning component processes each player’s last 10 matches as an independent time series. Shared LSTM weights encode a universal momentum representation — the same network processes both players, learning patterns that generalize across players rather than memorizing individual styles. O componente de deep learning processa as últimas 10 partidas de cada jogador como uma série temporal independente. Os pesos compartilhados do LSTM codificam uma representação universal de momentum — a mesma rede processa ambos os jogadores, aprendendo padrões que generalizam entre jogadores.
The momentum embeddings are concatenated with 23 context features (rank differential, surface, H2H) in a dense fusion layer. This hybrid design lets the LSTM handle temporal dynamics while the tabular path preserves interpretable context signals. Os embeddings de momentum são concatenados com 23 features de contexto (diferencial de ranking, superfície, H2H) em uma camada de fusão densa. Esse design híbrido permite que o LSTM capture dinâmicas temporais enquanto o caminho tabular preserva sinais de contexto interpretáveis.
Optuna Hyperparameter TuningOtimização de Hiperparâmetros com Optuna
The LSTM architecture was optimized using Optuna’s Bayesian TPE sampler across five hyperparameters: hidden size, number of layers, dropout rate, learning rate, and batch size. Bayesian search is substantially more sample-efficient than grid search when each trial requires a full training run — particularly relevant without GPU infrastructure. A arquitetura LSTM foi otimizada com o amostrador Bayesiano TPE do Optuna em cinco hiperparâmetros: tamanho oculto, número de camadas, dropout, taxa de aprendizado e tamanho de batch. A busca Bayesiana é substancialmente mais eficiente do que grid search quando cada trial exige uma execução completa de treinamento.
Early stopping on validation AUC prevented overfitting across trials. The final LSTM was trained from the best Optuna configuration before evaluation on the held-out 2024 test set. O early stopping no AUC de validação preveniu overfitting entre os trials. O LSTM final foi treinado a partir da melhor configuração do Optuna antes da avaliação no conjunto de teste 2024.
Stacking EnsembleEnsemble de Stacking
Four base models feed a stacking meta-learner (XGBoost) trained on out-of-fold validation predictions — never on training labels directly: Quatro modelos base alimentam um meta-aprendiz de stacking (XGBoost) treinado em previsões out-of-fold da validação — nunca diretamente nos rótulos de treino:
- Logistic Regression — linear baselineRegressão Logística — baseline linear
- Random Forest — calibrated with Platt scalingRandom Forest — calibrado com Platt scaling
- XGBoost — strongest individual modelXGBoost — modelo individual mais forte
- Siamese LSTM — sequential learner on raw match historiesSiamese LSTM — aprendiz sequencial em históricos brutos
ResultsResultados
All results evaluated on the unseen 2024 test season: Todos os resultados avaliados no conjunto de teste 2024 (não visto durante o treino):
| ModelModelo | Test AUC | AccuracyAcurácia | NotesNotas |
|---|---|---|---|
| Stacking EnsembleEnsemble de Stacking | 0.7168 | 65.35% | XGBoost meta-learner |
| XGBoost | 0.7185 | 65.23% | Strongest individual modelModelo individual mais forte |
| Siamese LSTM | 0.7140 | 65.50% | Raw sequences, no manual smoothingSequências brutas, sem suavização manual |
| Random Forest | 0.7112 | 65.00% | Platt-calibratedCalibrado com Platt scaling |
| Logistic Regression | 0.7086 | 65.05% | Linear baselineBaseline linear |
The academic literature places the statistical ceiling for ATP prediction at ~0.75–0.77 AUC. Closing this gap requires non-statistical signals — injuries, coaching changes, travel fatigue — not available in public match records. A literatura acadêmica situa o teto estatístico para previsão ATP em ~0.75–0.77 AUC. Fechar essa lacuna exige sinais não-estatísticos — lesões, mudanças de técnico, fadiga de viagem — não disponíveis em registros públicos.
Feature Importance (SHAP)Importância das Features (SHAP)
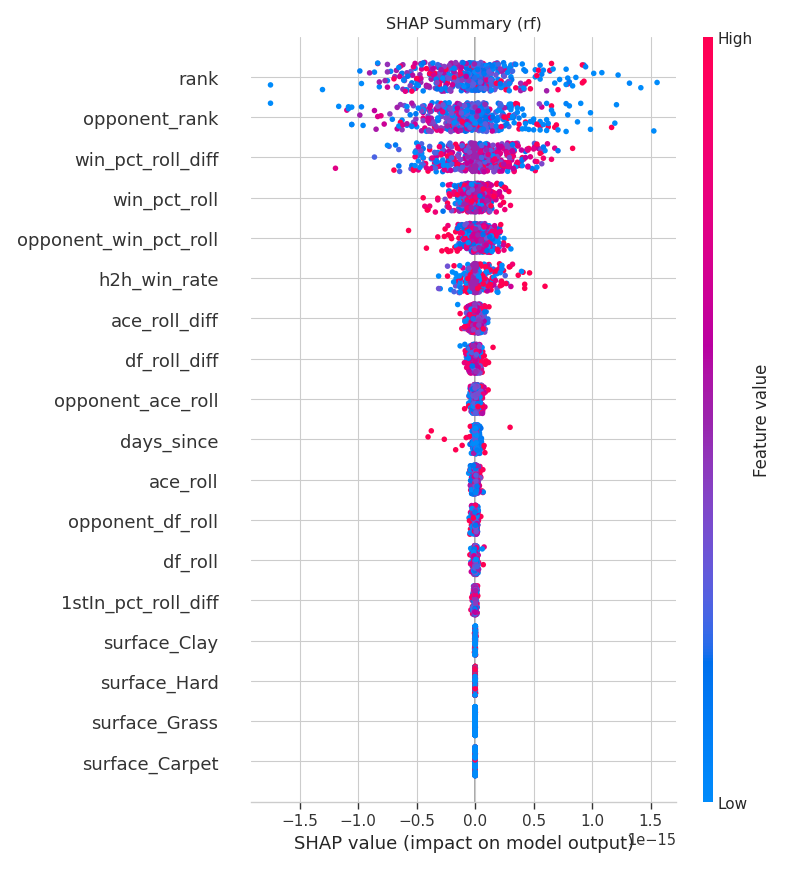
rank_pts_diff (log-transformed rank points differential, |r| = 0.338) is the strongest predictor, outperforming ordinal rank difference (0.228). Surface-specific rolling win rate and first-serve win percentage are next, confirming that recent surface form and serve dominance carry predictive signal beyond ranking alone. rank_pts_diff (diferencial de pontos de ranking com transformação logarítmica, |r| = 0,338) é o preditor mais forte, superando a diferença ordinal de ranking (0,228). A taxa de vitória por superfície e o percentual de pontos ganhos no primeiro saque vêm a seguir, confirmando que a forma recente por superfície e a dominância no saque carregam sinal preditivo além do ranking.
CalibrationCalibração
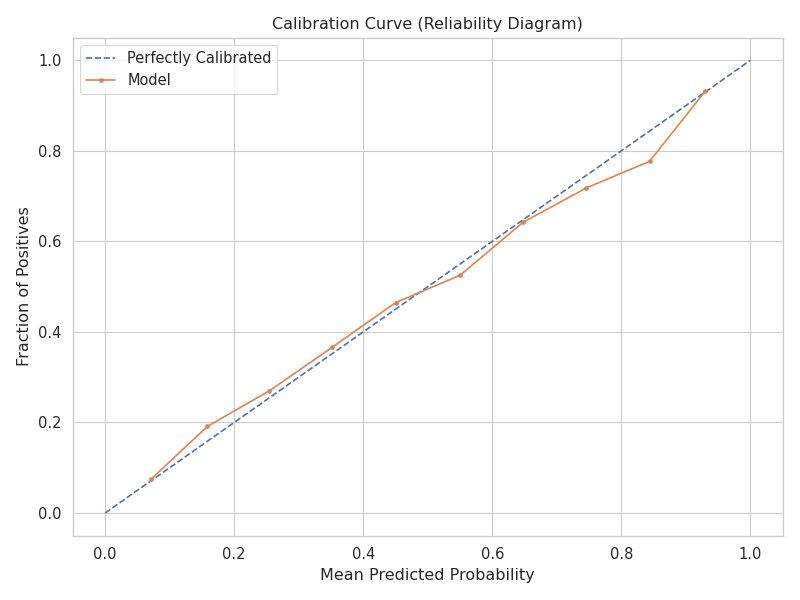
A calibrated model is one where predicted probabilities match empirical frequencies — when the model outputs 0.70, the predicted player wins approximately 70% of the time. The LSTM’s reliability diagram tracks the perfect calibration diagonal closely, a property that matters whenever downstream decisions depend on probability magnitude rather than binary classification. Um modelo calibrado é aquele em que as probabilidades previstas correspondem às frequências empíricas — quando o modelo produz 0,70, o jogador previsto vence aproximadamente 70% das vezes. O diagrama de confiabilidade do LSTM acompanha de perto a diagonal de calibração perfeita, uma propriedade importante quando decisões subsequentes dependem da magnitude da probabilidade.
ConclusionConclusão
- A full ML pipeline — from raw sequential data to stacking ensemble — built with strict temporal validation at every step, eliminating the look-ahead bias that invalidates most published sports forecasting results.Um pipeline completo de ML — de dados sequenciais brutos a ensemble de stacking — construído com validação temporal rigorosa em cada etapa, eliminando o viés de look-ahead que invalida a maioria dos resultados publicados em previsão esportiva.
- A Siamese LSTM that learns momentum representations from raw sequences, matching a carefully engineered tabular baseline without any manual feature construction.Um Siamese LSTM que aprende representações de momentum a partir de sequências brutas, igualando uma baseline tabular cuidadosamente engenheirada sem construção manual de features.
- Optuna Bayesian hyperparameter search applied to the LSTM — more sample-efficient than grid search when each trial requires a full training run.Busca Bayesiana de hiperparâmetros com Optuna aplicada ao LSTM — mais eficiente do que grid search quando cada trial exige um treinamento completo.
Stack: Python · PyTorch · Optuna · XGBoost · Scikit-Learn · Pandas · SHAP | View on GitHub → Ver no GitHub → | ← Back to Projects ← Voltar aos Projetos