Credit Risk Optimization Engine: Profit-First Loan Approval
The Problem with Optimizing AccuracyO Problema de Otimizar Acurácia
A model that predicts “fully paid” for every single applicant achieves 84% accuracy on this dataset — because 84% of loans are actually repaid. That model is useless. It approves every default and leaves $330,145 in recoverable profit on the table. Um modelo que prevê “pagamento total” para todos os solicitantes atinge 84% de acurácia neste dataset — porque 84% dos empréstimos são de fato pagos. Esse modelo é inútil. Ele aprova todos os inadimplentes e deixa $330.145 em lucro recuperável na mesa.
Standard classification metrics — accuracy, F1-score — are blind to the asymmetry of credit risk. A missed default costs far more than a rejected good applicant. The correct objective function is portfolio net profit, not classification accuracy. Métricas padrão de classificação — acurácia, F1-score — são cegas à assimetria do risco de crédito. Um default perdido custa muito mais do que um bom solicitante rejeitado. A função objetivo correta é o lucro líquido do portfólio, não a acurácia de classificação.
This project builds a credit scoring engine that makes that substitution explicitly — replacing the classification threshold with a profit-maximizing approval rate, grounded in the actual P&L structure of the loan portfolio. Este projeto constrói um motor de scoring de crédito que faz essa substituição explicitamente — trocando o threshold de classificação por uma taxa de aprovação que maximiza o lucro, fundamentada na estrutura real de P&L do portfólio de empréstimos.
Financial Engineering: Reconstructing the AssetEngenharia Financeira: Reconstruindo o Ativo
The dataset provides monthly installment amounts and interest rates, but not the loan principal — the capital at risk in a default scenario. Before any modeling, the principal must be derived. I applied the Present Value of an Annuity formula, assuming a 36-month fixed term: O dataset fornece valores de parcelas mensais e taxas de juros, mas não o principal do empréstimo — o capital em risco em um cenário de inadimplência. Antes de qualquer modelagem, o principal deve ser derivado. Apliquei a fórmula do Valor Presente de uma Anuidade, assumindo prazo fixo de 36 meses:
\[P = A \times \frac{1 - (1 + r/12)^{-36}}{r/12}\]
where \(A\) is the monthly installment and \(r\) is the annual interest rate. This engineered principal feature becomes the foundation of the profit function — it defines exactly how much capital is lost when a loan defaults. onde \(A\) é a parcela mensal e \(r\) é a taxa de juros anual. Essa feature engenheirada principal torna-se a base da função de lucro — ela define exatamente quanto capital é perdido quando um empréstimo entra em default.
The Profit FunctionA Função de Lucro
Each loan approval decision maps to one of three financial outcomes: Cada decisão de aprovação de empréstimo mapeia para um de três resultados financeiros:
| OutcomeResultado | FormulaFórmula | InterpretationInterpretação |
|---|---|---|
| Approved, repaid (TN)Aprovado, pago (TN) | \((installment \times 36) - principal\) | Total interest incomeReceita total de juros |
| Approved, defaulted (FN)Aprovado, inadimplente (FN) | \((principal \times 0.30) - principal = -0.70 \times principal\) | Net loss after 30% recoveryPerda líquida após 30% de recuperação |
| Rejected (any class)Rejeitado (qualquer classe) | \(0\) | Opportunity cost — no gain or lossCusto de oportunidade — sem ganho ou perda |
The 30% recovery rate reflects industry approximations for unsecured consumer debt. Assumptions not modeled: cost of capital (assumed 0%), time value of money, and prepayment risk — all documented as future work. A taxa de recuperação de 30% reflete aproximações do setor para dívida não garantida ao consumidor. Premissas não modeladas: custo de capital (assumido 0%), valor do dinheiro no tempo e risco de pré-pagamento — todos documentados como trabalho futuro.
The Strategy CurveA Curva de Estratégia
The core of the engine is not a classifier — it is a strategy curve: a sweep across 200 candidate thresholds (0.01–0.99) that computes realized portfolio profit at each approval rate. A loan is approved when its predicted default probability falls below the threshold. The optimal threshold is determined empirically per model, not fixed at 0.5. O núcleo do motor não é um classificador — é uma curva de estratégia: uma varredura por 200 thresholds candidatos (0,01–0,99) que computa o lucro realizado do portfólio em cada taxa de aprovação. Um empréstimo é aprovado quando sua probabilidade prevista de default está abaixo do threshold. O threshold ótimo é determinado empiricamente por modelo, não fixado em 0,5.
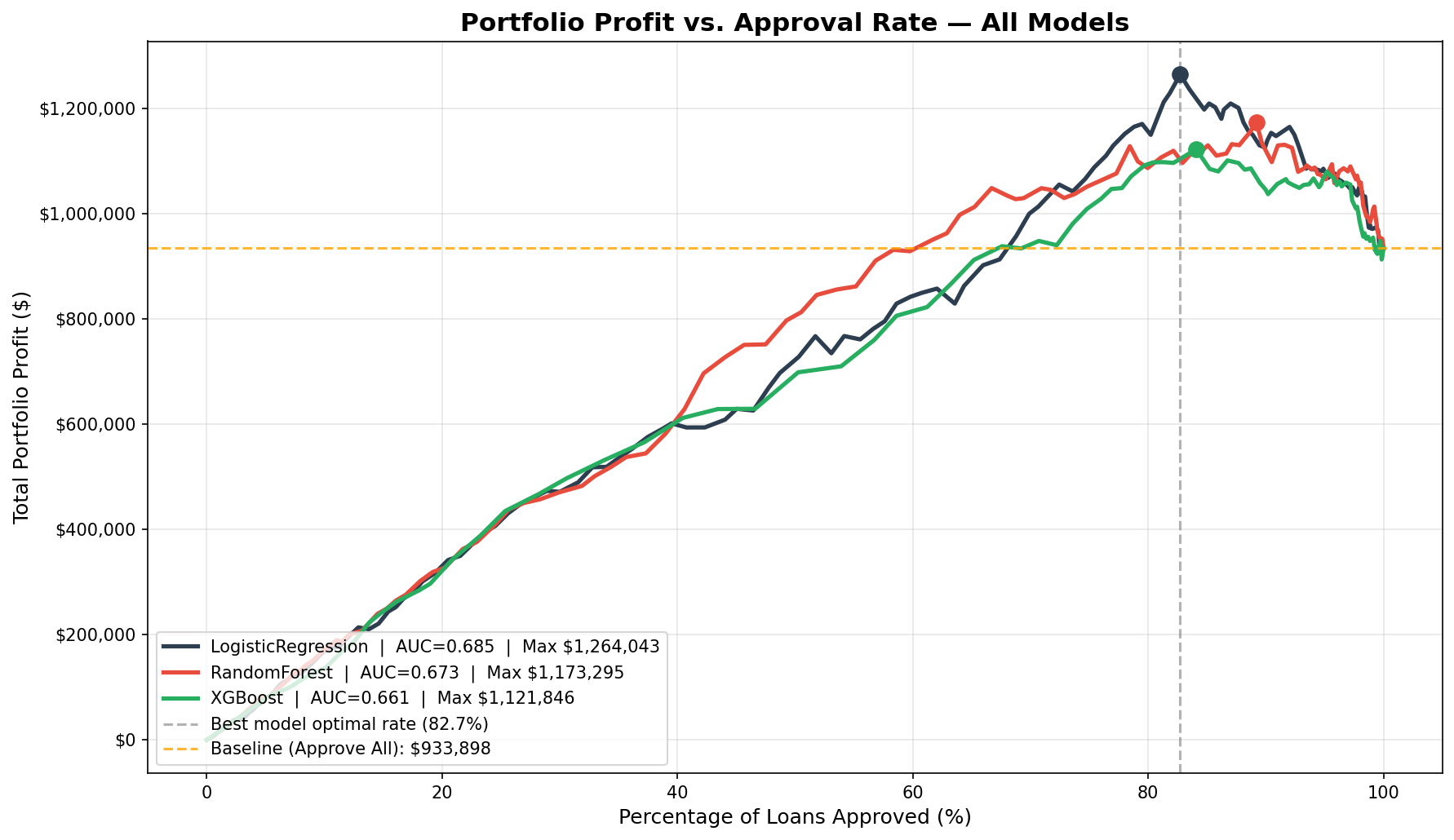
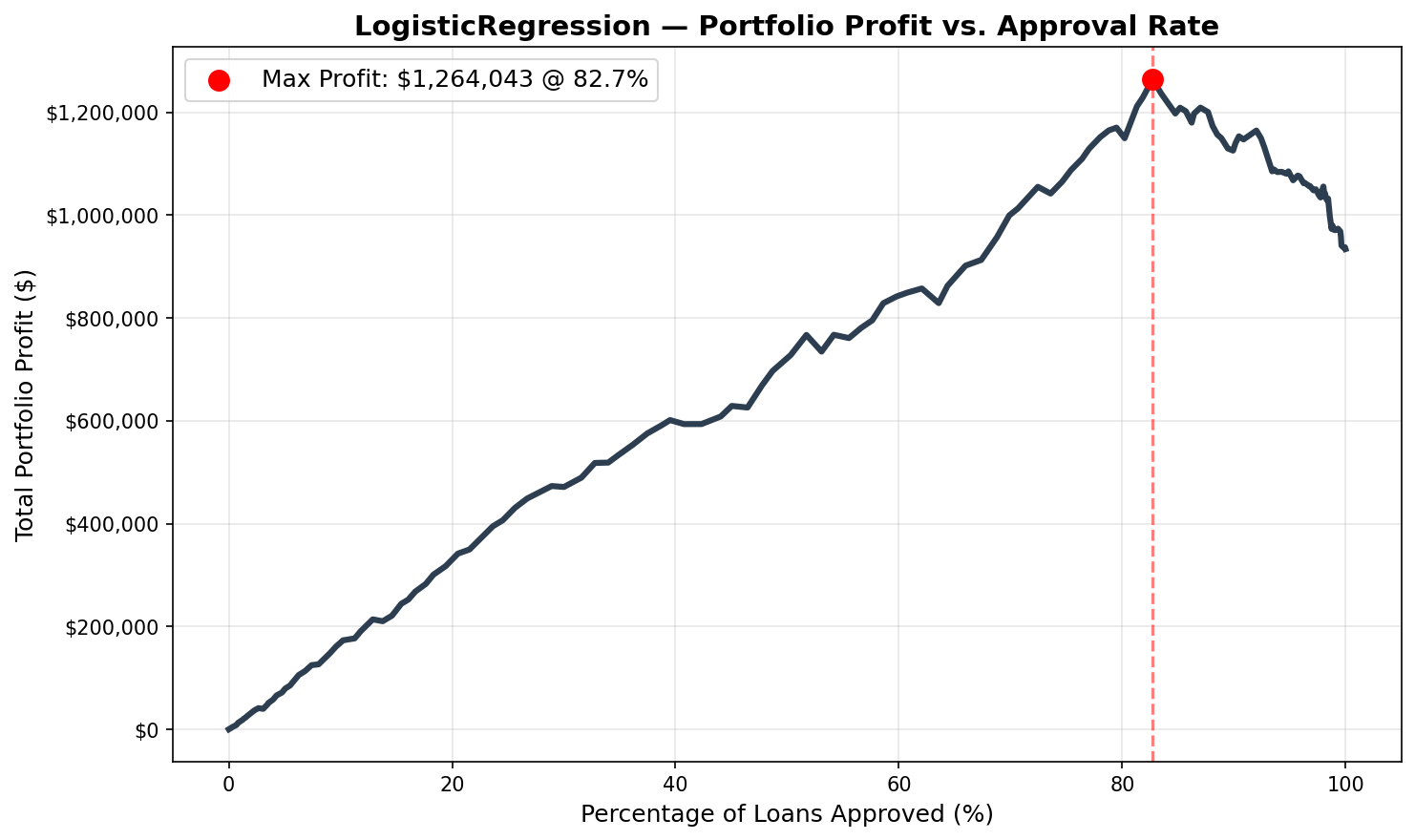
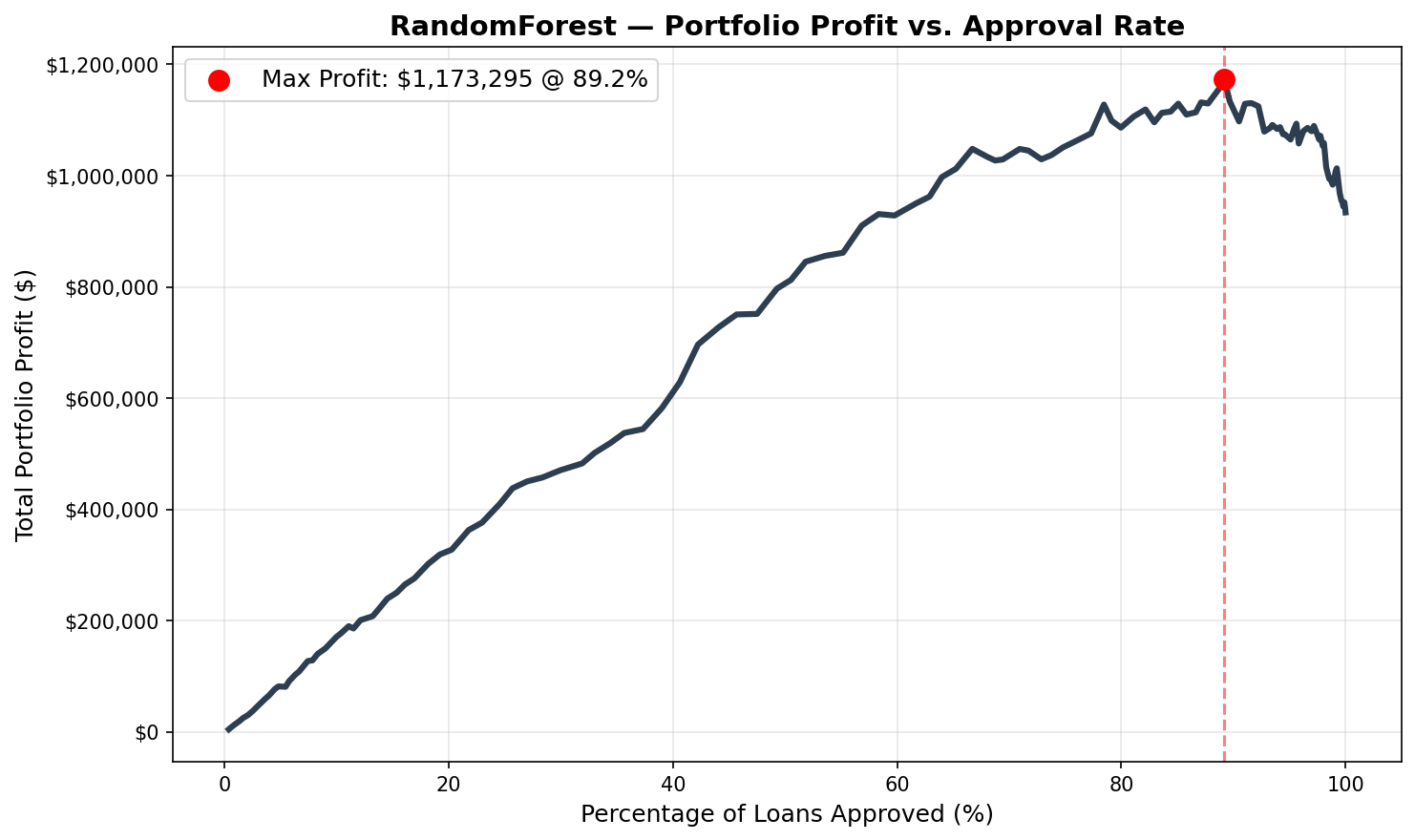
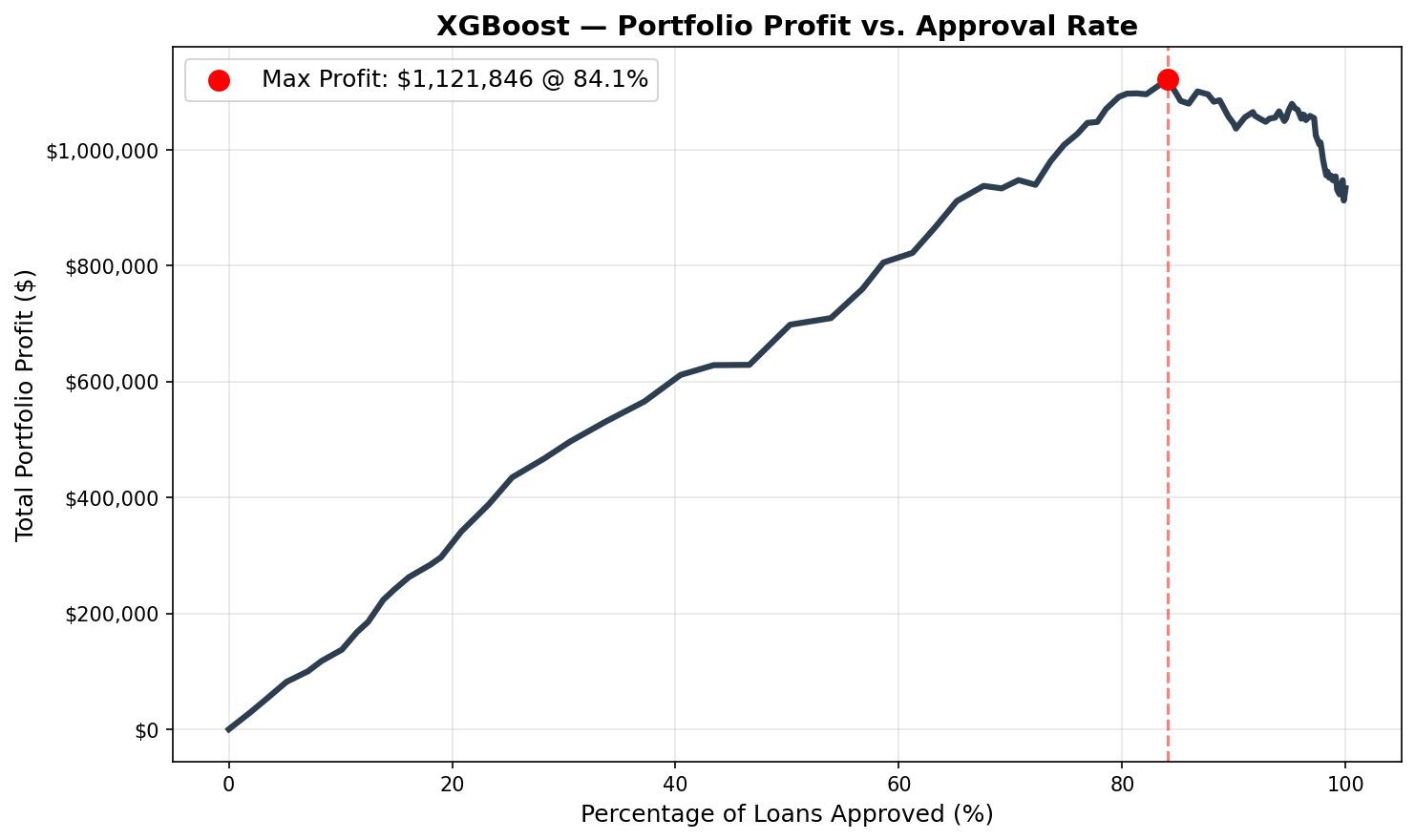
The comparison above shows all three models against the naive baseline ($933,898 — approve all applicants). Every model outperforms the baseline at its optimal threshold. Logistic Regression achieves the highest portfolio profit despite having the lowest raw accuracy — a result that requires explanation. A comparação acima mostra os três modelos versus a baseline ingênua ($933.898 — aprovar todos os solicitantes). Cada modelo supera a baseline no seu threshold ótimo. A Regressão Logística atinge o maior lucro do portfólio apesar de ter a menor acurácia bruta — um resultado que requer explicação.
Model BenchmarkingBenchmarking de Modelos
Three models were tuned via RandomizedSearchCV (35 iterations, 3-fold CV, AUC scoring) on an 80/20 stratified split. All models handle the 16% default class imbalance explicitly — Logistic Regression and Random Forest via class_weight='balanced'; XGBoost via scale_pos_weight. Três modelos foram ajustados via RandomizedSearchCV (35 iterações, CV de 3 folds, scoring por AUC) em uma divisão estratificada 80/20. Todos os modelos tratam explicitamente o desbalanceamento de 16% da classe de default — Regressão Logística e Random Forest via class_weight='balanced'; XGBoost via scale_pos_weight.
All results verified on the held-out 2024 test set (1,916 loans): Todos os resultados verificados no conjunto de teste (1.916 empréstimos):
| ModelModelo | AUC | AccuracyAcurácia | Optimal ThresholdThreshold Ótimo | Approval RateTaxa de Aprovação | Portfolio ProfitLucro do Portfólio | ROI LiftGanho de ROI |
|---|---|---|---|---|---|---|
| Logistic Regression | 0.685 | 64.0% | 0.606 | 82.7% | $1,264,043 | +35.4% |
| Random Forest | 0.673 | 82.2% | 0.453 | 89.2% | $1,173,295 | +25.6% |
| XGBoost | 0.661 | 83.7% | 0.246 | 84.1% | $1,121,846 | +20.1% |
| Baseline (approve all)Baseline (aprovar tudo) | — | 84.0% | — | 100% | $933,898 | — |
Why Logistic Regression WinsPor Que a Regressão Logística Vence
XGBoost achieves 83.7% accuracy — but look at its confusion matrix: it assigns recall of 0.01 to the default class, meaning it correctly identifies almost no defaults. It achieves high accuracy by predicting “fully paid” for nearly everyone, which is identical to the naive baseline in behavior. High accuracy here is a symptom of the problem, not a solution to it. O XGBoost atinge 83,7% de acurácia — mas observe sua matriz de confusão: ele atribui recall de 0,01 à classe de default, significando que identifica corretamente quase nenhum inadimplente. Atinge alta acurácia prevendo “pagamento total” para quase todos, o que é idêntico ao comportamento da baseline ingênua. Alta acurácia aqui é um sintoma do problema, não uma solução.
Logistic Regression with class_weight='balanced' accepts lower overall accuracy (64%) in exchange for genuine sensitivity to defaults (recall=0.58). The class_weight adjustment re-weights the loss function so that misclassifying a default is penalized proportionally to its financial cost. This is the correct behavior when the objective is profit, not classification score. A Regressão Logística com class_weight='balanced' aceita menor acurácia geral (64%) em troca de sensibilidade genuína aos inadimplentes (recall=0,58). O ajuste de class_weight reponde à função de perda para que classificar incorretamente um default seja penalizado proporcionalmente ao seu custo financeiro. Esse é o comportamento correto quando o objetivo é lucro, não pontuação de classificação.
Model AnalysisAnálise do Modelo
ROC CurvesCurvas ROC
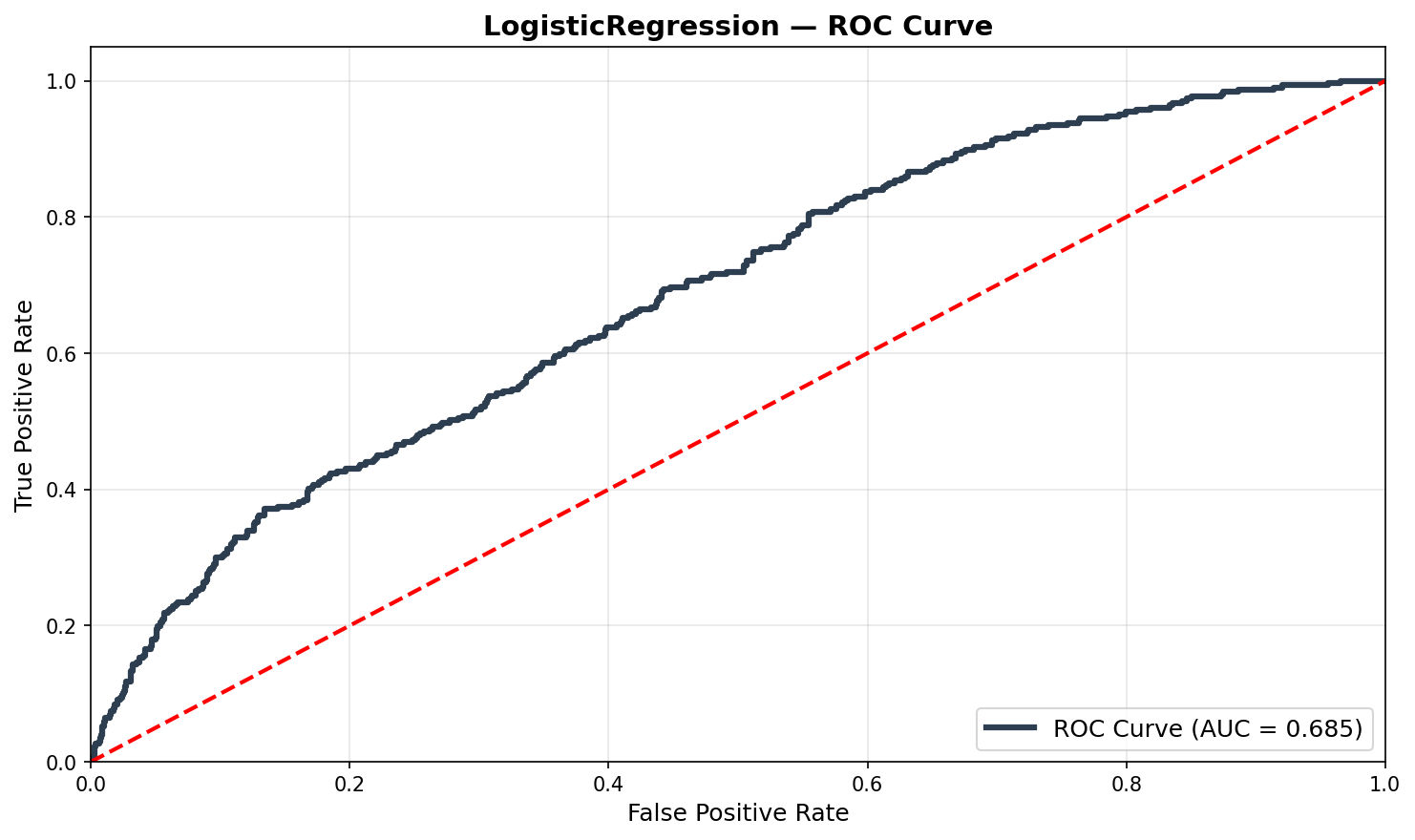
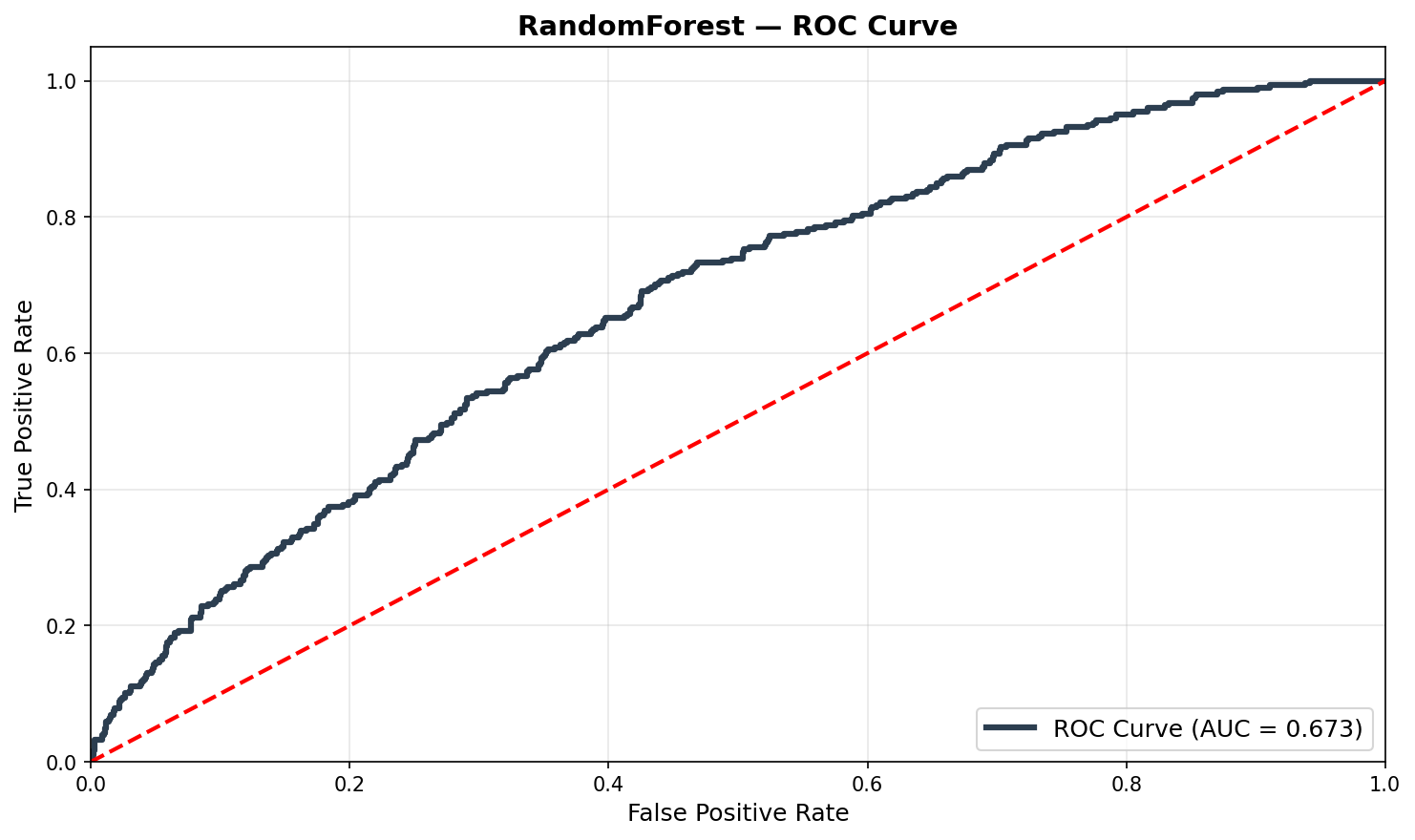
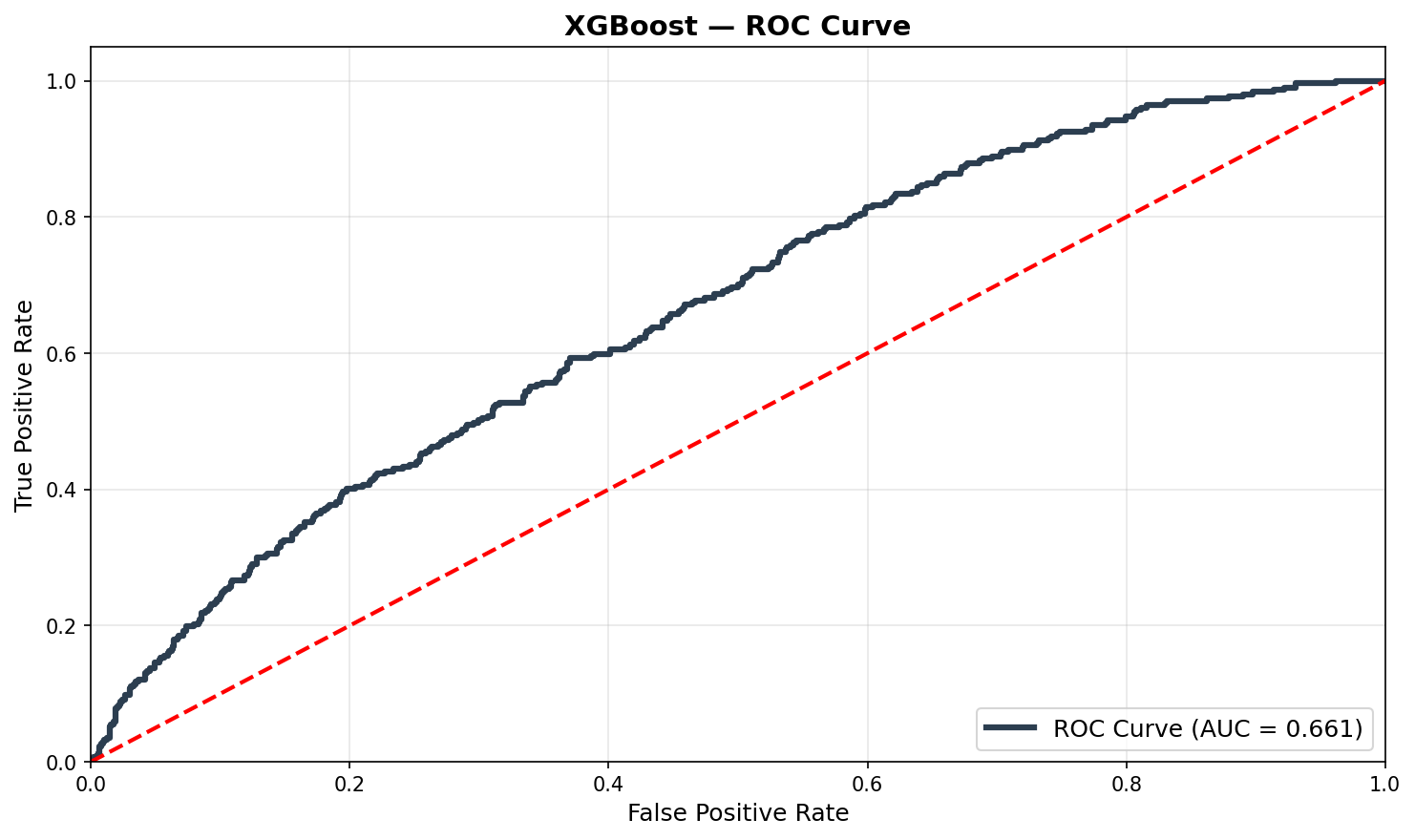
Feature Importance (SHAP)Importância das Features (SHAP)
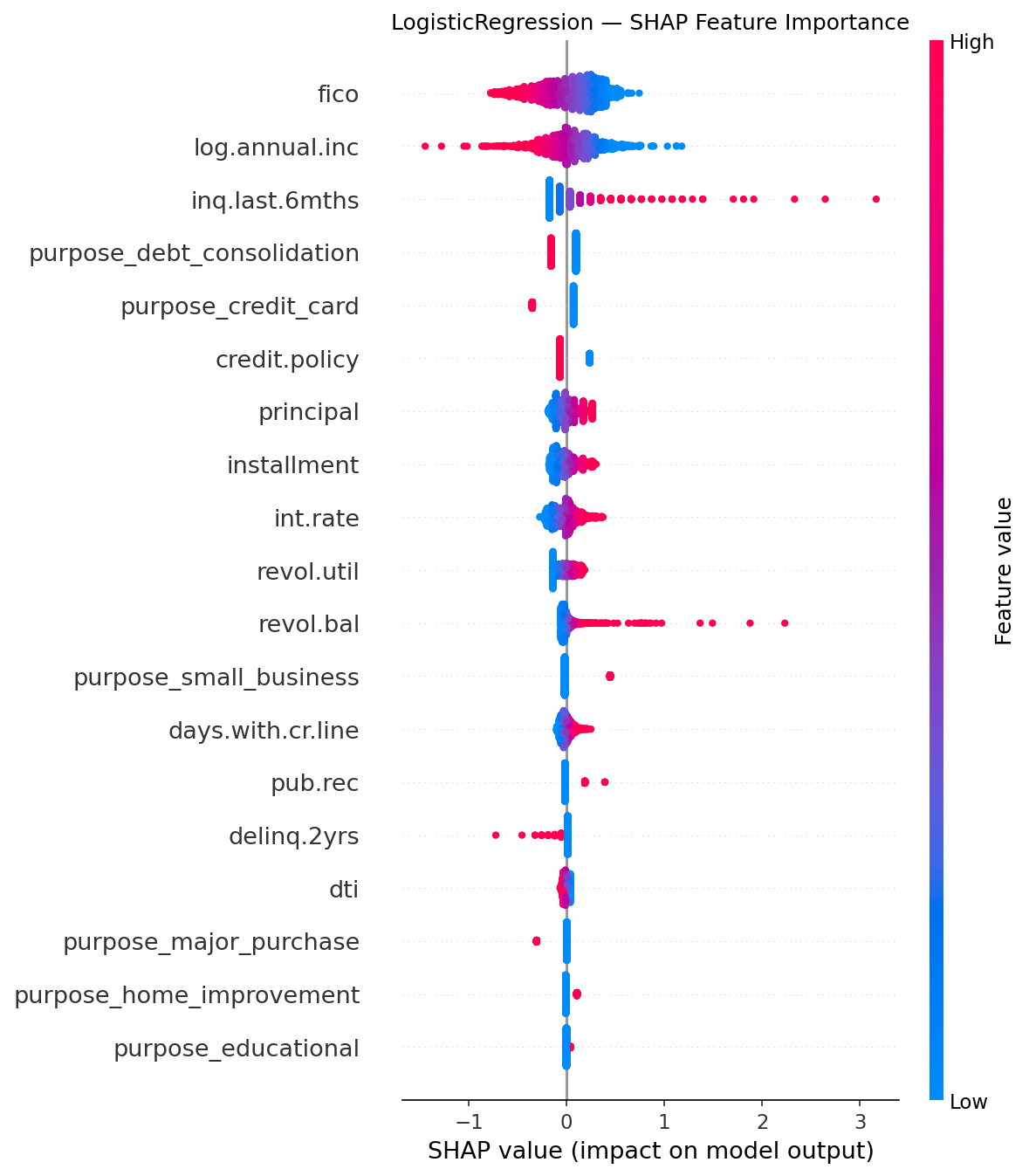
SHAP analysis on the selected Logistic Regression model reveals three dominant risk drivers: A análise SHAP no modelo de Regressão Logística selecionado revela três principais fatores de risco:
FICO score is the strongest monotonic predictor of creditworthiness — higher scores strongly reduce predicted default probability, consistent with its role as a standardized creditworthiness signal. O FICO score é o preditor monotônico mais forte de solvência — scores mais altos reduzem fortemente a probabilidade prevista de default, consistente com seu papel como sinal padronizado de crédito.
Credit inquiries in the last 6 months (inq.last.6mths) is the second most important feature. High credit-seeking velocity is a well-documented distress signal — applicants approaching multiple lenders simultaneously are more likely to be facing liquidity constraints. Consultas de crédito nos últimos 6 meses (inq.last.6mths) é a segunda feature mais importante. Alta velocidade de busca de crédito é um sinal documentado de dificuldade financeira — solicitantes que abordam múltiplos credores simultaneamente têm maior probabilidade de enfrentar restrições de liquidez.
Interest rate (int.rate) confirms that riskier loans are priced higher — but also that the risk premium embedded in the rate is often insufficient to offset default losses in the lowest credit quality deciles, where rejecting the applicant outright is more profitable than extending credit. Taxa de juros (int.rate) confirma que empréstimos mais arriscados têm precificação mais alta — mas também que o prêmio de risco embutido na taxa frequentemente é insuficiente para compensar as perdas por default nos decis de menor qualidade de crédito, onde rejeitar o solicitante é mais lucrativo do que conceder crédito.
Individual Strategy CurvesCurvas de Estratégia Individuais
ConclusionConclusão
- Reframed loan approval as a financial optimization problem — replacing accuracy with portfolio net profit as the objective function, grounded in the P&L structure of the loan asset.Reformulou a aprovação de empréstimos como um problema de otimização financeira — substituindo acurácia por lucro líquido do portfólio como função objetivo, fundamentada na estrutura de P&L do ativo de empréstimo.
- Derived loan principal from installment data using the PV of an annuity formula — enabling a realistic profit calculation where none was possible with raw features alone.Derivou o principal do empréstimo a partir dos dados de parcelas usando a fórmula do VP de uma anuidade — possibilitando um cálculo de lucro realista onde nenhum era possível com as features brutas.
- Demonstrated that high accuracy (84% for XGBoost) can be financially worse than lower accuracy (64% for Logistic Regression) — when the model with high accuracy achieves it by ignoring the minority class that drives the most capital loss.Demonstrou que alta acurácia (84% para XGBoost) pode ser financeiramente pior do que menor acurácia (64% para Regressão Logística) — quando o modelo com alta acurácia a alcança ignorando a classe minoritária que gera as maiores perdas de capital.
Stack: Python · scikit-learn · XGBoost · pandas · SHAP · Matplotlib | View on GitHub → Ver no GitHub → | ← Back to Projects ← Voltar aos Projetos